- Starter AI
- Posts
- Deep Dive: Building GPT from scratch

Welcome to the Deep Dive into GPTs series of Starter AI.
If you can code and you’d like to learn AI from scratch, this series is for you.
Who am I, and why write this?
My name is Miko Pawlikowski, and I spent the last decade building platforms & doing SRE. You might have seen my book on Chaos Engineering, and you might have bumped into me at SREday. I love that stuff, and most of my writing is about that.
So what’s up with AI?
2023 was a breakthrough year for LLMs (Large Language Models). Humanity as a whole figured out that taking a massive amount of text and processing it with a large stash of GPUs allows for the creation of an entirely new breed of software. The kind of software that feels creepily “human”: answer questions, write code, summarise text, translate, and do what really looks like logical reasoning.
All of that came after 2022 brought a different kind of breakthrough: stable diffusion. The two together laid foundations for projects like Midjourney, which can generate images (photorealistic, or in nearly any style) from a single prompt. Things are getting weird.
And it turns out that achieving these results is not as difficult as the science fiction writers had us think (Google’s memo about having ‘no moat’ underlines that).
So while I still don’t think Skynet is just around the corner (I hope this ages well), last year was when I realised that this new tech is here to stay, and it’s time to learn it. Whether we’re entering the AI era, after smartphones, after the internet, remains to be seen. But from a programmer’s point of view, the landscape has shifted, even after the hype dies down.
So in this series of Starter AI, I’ll be sharing with you my journey on how to learn it. It’s hard to learn a new domain from scratch while working full time, and it’s even harder with the informational overload happening currently in AI.
So my hope is that lining things up for you, and motivating you to push will maximise your chances of succeeding.
So, where do we start?
Enter Andrej Karpathy
If you ever googled anything AI, Andrej’s name probably came up.
What makes him stand out from the crowd of deep learning geniuses is that when he’s not busy being a founding member of OpenAI, or Senior Director of AI at Tesla, or jumping back to OpenAi, he’s sharing a lot of what he learns online, for free.
Check out his homepage: https://karpathy.ai/
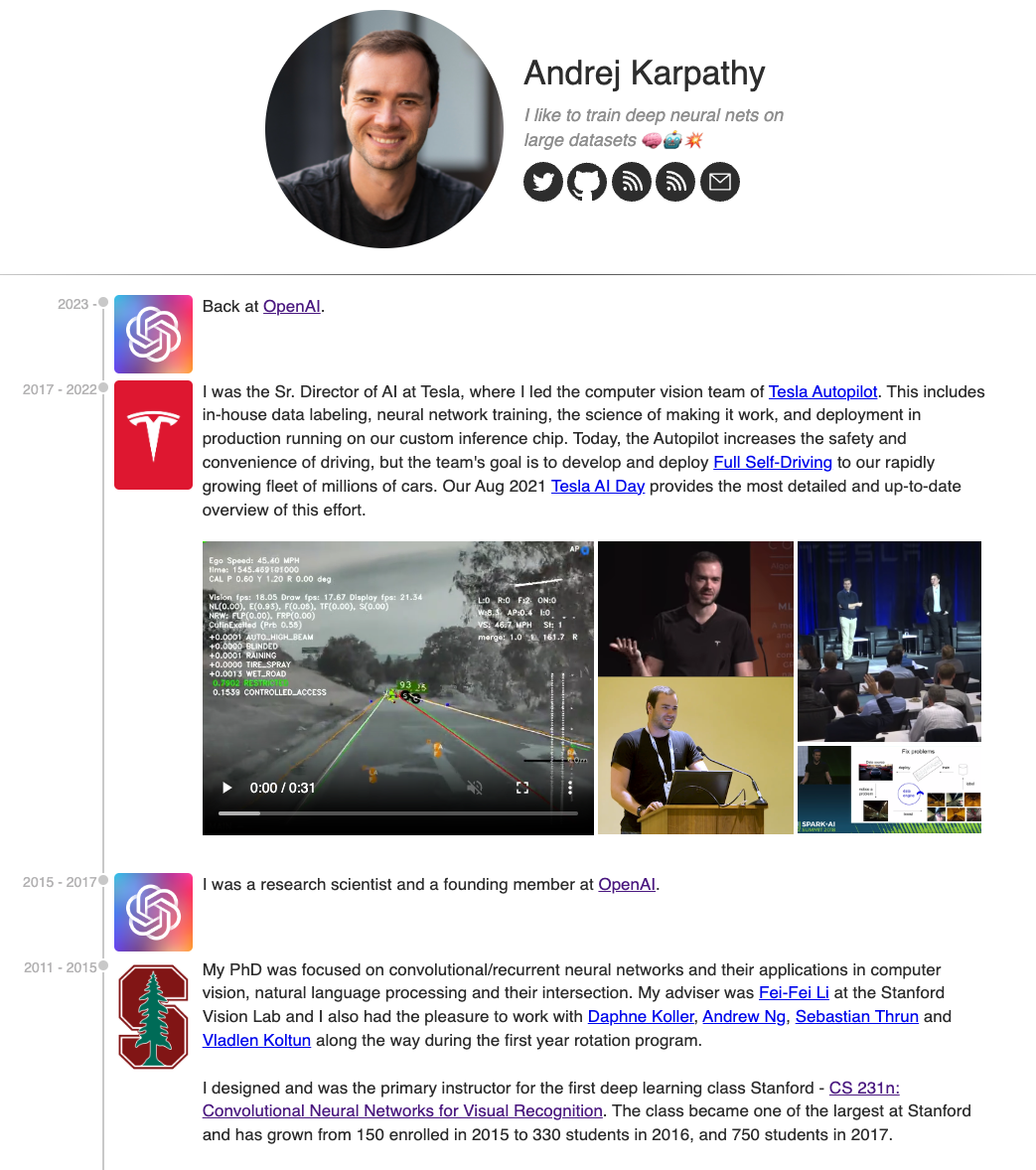
Andrej’s homepage
He also doesn’t project an aura of a millionaire tech founder, but rather a down-to-earth guy who’s really excited about his area of expertise. Which only adds to the respect.
The amount of learning resources on AI is increasing very rapidly. But I found Andrej’s videos the most manageable to learn from. In the last six months or so, I’ve gone through his videos, and learned a ton.
I said manageable, but the material is still rather dense. And just like it is with every new domain in software, there is a lot to take in: new tools, frameworks, jargon, and.. yes… occasional bit of maths.

imgflip.com
The roadmap
In the coming weeks, we’re going to follow Andrej’s Zero To Hero videos, taking detours for simple software engineers like myself to understand some concepts he skips over. Some of these videos are around 2 hours long, so we’re going to split those into smaller chunks.
The goal of this series is to implement a GPT from scratch, and to actually understand everything needed to do that.
Today: Neural Networks & Backpropagation part 1
If you’d like to follow along, make sure you follow me on LinkedIn & subscribe to the newsletter at starterai.dev.
The only prerequisite is to be able to read/write basic python.
Neural Networks & Backpropagation part 1
Today we’ll watch the first part of Andrej’s lecture called “The spelled-out intro to neural networks and backpropagation: building micrograd”. I always thought that the ultimate flex is to build a bare-bones, simple version of something that people are paying millions of dollars for, put it on github for free, and film yourself doing that.
In this video, Andrej is doing that for the minimum of NN we need to understand for building an LLM, and the result is micrograd. Have a browse on github - this is what we’ll be building up to in his lecture.
Start watching, and below is some extra context that will come in useful.
Context
Jupyter notebooks is a popular way of interacting with, and sharing, python code through a UI. In the video, he starts with a local notebook that you can install like this.
PyTorch is a popular machine learning framework. It seems to be liked in particular for the ease of use. Watch these 100 seconds for a super high-level idea. The name’s because it’s a port/continuation of another library, Torch, written in Lua. Since 2022, it’s governed by PyTorch foundation, an independent organisation that’s a subsidiary of the Linux Foundation. It’s in Meta’s best interest to have an open alternative to TensorFlow controlled by Google. You will see PyTorch all over the place.
PyTorch is not the only ML framework in town (Andrej mentions JAX), but according paperswithcode.com it’s dominant, at least on github code:

Autograd, or automatic gradient appears to be accepted in PyTorch community as interchangeable with automatic differentiation, or autodiff. Watch this video for an intro to autodiff. Autograd is also the name of a PyTorch function doing the same. Backpropagation is technically a special case of automatic differentiation but it also seems to be used synonymously with autodiff.
Numpy is a popular python framework for numerical computing.
Scalars are basically variables (mathematicians, please don’t kill me!)
Graphviz is the plotting library he’s using in the video.
Chain rule (calculus). What you/me should have learnt back in school. Andrej explains that in detail.
Takeways
You will learn (timestamps should be clickable):
00:00:25 Overview of the micrograd project & motivation for the video
00:08:08 How to manually derive simple function in python numerically
00:14:12 Deriving a function with multiple parameters, with respect to each parameter
00:19:09 Actually building micrograd - Value object, building the graph
00:25:02 Visualisation of the graph with graphviz
00:32:10 Manual backpropagation example #1: simple expression
00:52:52 Manual backpropagation example #2: a neuron
And then we’ll take a break at around 1h 9 min mark until next time.
Summary
You’ve just seen Andrej explain what a neural network actually is, and gradually show you how to manually calculate the gradients for backpropagation. You’ve just done your first hour of AI. Only 9,999 left!
You should now be able to answer these questions:
Today you can mostly get away with just watching and learning, but be prepared - next time we’ll need to get our hands dirty.
Well done, you’ve taken the first step to learn yourself some AI!

What’s next
Next week we’ll finish up the video, use PyTorch for the first time, and actually train a neural network. We’ll run the tests, using PyTorch as a reference.
In the meantime, check out the links in the context section to get yourself ready.
Next episodes will be sent through the newsletter at starterai.dev, so subscribe if you haven’t already.
Please leave a like on his video, and don’t forget to share this with friends!
Feedback
How did you like it? Was it easy to follow? What should I change for the next time?
Please reach out on LinkedIn and let me know!
How did you like this issue? |